Migration Data Extracts
A Guide to Understanding Your Data Extract
In your legacy application, your data is stored in fields, and those fields have different properties depending on the type of data in the field. Some fields are unformatted, allowing you to enter a long string of text. You may have specific formatting in a phone number field to ensure that all your contact information is entered in a consistent manner. You may have a currency field to record and total amounts of money recovered on a claim. You may have fields that limit the options a user can select, like a dropdown, a radio button, or a toggle. Field types are important because they place limits on how data is formatted, and also save users time when making selections (like being able to choose a date from a calendar, rather than typing it out).
When this data is extracted from your system, it’s stored in a .csv, which is a document that will list all your values in one long line, with each one separated by a comma. The type of field the data comes from doesn’t apply in the .csv, as all the values are represented as strings of text. When your legacy data is migrated into the new system, we need to ensure that we account for the field type so that the value can be converted back to the correct format, and that the type in your legacy system is compatible with the type in the new application. For instance, we wouldn’t be able to migrate a string of text from a free text field into a set of radio button values. This guide outlines the most common field types and the factors that need consideration in your migration.
Booleans
A Boolean is something that can be one thing or another; not neither, and not both. In your user interface, you will see Booleans displayed as checkboxes, radio buttons, and toggles, and the values for these fields usually correspond to the following pairs: yes/no, on/off, and true/false. How these values are stored in the database is what provides the challenge during migration; while on the front end the field options could be Yes and No, on the back end the field values could be stored as true and false, 1 and 0, or yes and no – none of which are exact matches for what you see on the front end.

Dates and Times
Formatting errors with dates are the most common issues encountered when migrating data from one database to another, especially if the field or row where users enter the date doesn’t limit them to a specific format. Unless it’s specified, the script migrating the date 10/06/12 into the new application has no way of telling whether this date is October 6th 1912, or the 6th of June, 2012. Depending on the format used, the year could even be 1910, 2010, 1906, or 2006.
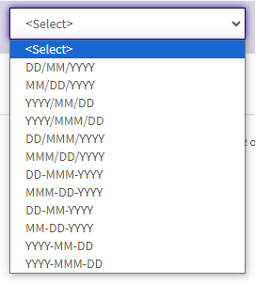
You will need to ensure that every date column has dates that follow the same format. Case IQ will accept many different formats for dates (see screenshot at right for examples), but that format must apply system-wide. So that means that not only do all the dates in a column in your extract have to be consistent in their format, but that format has to be the same across all date columns in your database.
The need for consistency applies as well if you use times in your system. While more limited, times are usually displayed in either 12-hour or 24-hour format, and this needs to be the same across your records.
If you have users recording data in different time zones, these time zones need to be indicated in the data (sometimes information like this is not visible on the front end but is stored in the database as metadata). If it isn’t specified, then the data will be migrated into the Case IQ application under a single time zone, and this could have the effect of changing some of your dates.
Special Characters and UTF-8 Encoding
A special character is defined as a symbol that is neither a number or a letter. Non alphanumeric characters can include things like formatting characters such as paragraph marks, punctuation, mathematical symbols, and accent marks.
Many special characters, because they are not contained in the standard QWERTY keyboard, need to be coded in by typing in a sequence – in Microsoft, using CTRL + , and then entering a c will provide you with the ç character. Other characters are entered by using ALT + a 4-digit code (e.g. ALT + 0209 will give you Ñ). Still others use html coding: Æ will render as Æ, for example. Depending on how they are encoded into your database, they may display differently or incorrectly when they are imported into the Case IQ database. Complex Chinese characters, and other alphabets which are written from right to left or from top to bottom, can pose a challenge in their encoding as well.
A very common encoding error is related to dashes (-, –, –, etc.) because they all look very similar from the front end. This typically causes errors if you are trying to map one type of dash to another, unintentionally.
We can avoid many of these encoding issues by ensuring that your data extract is formatted in UTF-8 encoding. UTF stands for “Unicode Transformation Format” and UTF-8 is a commonly-used version of this format that encodes all characters into an 8-digit binary string (e.g. “A” is encoded in UTF-8 as “010000001”). Case IQ can easily translate this binary string back to its original character.
HTML Formatting
Any formatting applied to text, like making it bold or italicized, listed out with bullets, or even simply with paragraphs in-between, has HTML formatting applied to it to ensure that when it’s viewed over the internet, the same formatting displays regardless. When you move text from a field that allows for this type of formatting (in Case IQ, this is the Text Editor type field) to a plain text field (like a text area or text box), then the formatting itself becomes visible – for example, bold will display as <b>bold</b>. This often occurs as well when migrating emails from one system to another, as they may be stored as an email with HTML formatting in the legacy system, but through the extract and migration process, will be consumed into the new system as text.
It’s important to be aware of when you are migrating a formatted block of text into a non-formatted field type so that the HTML formatting can be stripped out.
Delimiters
A delimiter is a character that is used to separate one record from another in the extract. In fact, the extract file is saved as a .csv, which stands for “comma separated values,” although there are other characters other than commas used to separate each record. It’s the variety of separators, or delimiters, used that can cause issues in migrations. Other delimiters, aside from commas, include double quotation marks (“) and single quotation marks or apostrophes (‘). The issue with each of these delimiters is that they appear often in blocks of narrative text. If there is a paragraph that includes an open quote or apostrophe but does not include a closing one, then in many cases the migration will assume that all the data between the open quote and the next closed quote (even if that appears several records later) is all one single record.
The best way to ensure that this doesn’t happen is to use an uncommon delimiter. Our recommendation is to use a pipe (|) as a delimiter because it is not a character that appears often in narrative text blocks and can serve as a unique identifier to the migration as to where a record begins and ends.
Phone Number
Phone numbers in Case IQ are formatted specifically to include a ten-digit number with area code in brackets. If your legacy phone numbers don’t match this field exactly, then the number won’t display correctly. In these cases, it’s easiest to migrate to a text field that does not force any formatting. Generally, phone numbers are not something people use in reporting metrics, so this is less of a critical issue for most customers, but something that needs to be addressed if you are migrating into a phone number field type.
Blanks
Sometimes a field is empty, and in most situations, a field with no data in it will migrate as empty into the new system. In some instances, no data in a field might be stored in your database as “null” or “N/A” – this means that when it’s extracted into a string of text, the field will now contain “null” as a value. For most narrative fields, this is not a major concern, as users will be able to identify that there is no real data of value in that field. For fields that are required – that is, fields that must be populated with data to allow you to save the case – a displayed value of “null” would satisfy the requirement and allow the case to be saved without adding real data to that field.
On a related note, if a field in the new system is required for case intake and it migrates as empty, then users will have to fill in that field before they can update and save the case for the first time, post-migration.
Joins and UUIDs
Your data is stored in a set of tables that have varying relationships to each other: your user table is related to your case table, for instance, because each case has a case owner assigned. The relationship between the tables is indicated as a join, which is a coded query in the database. When migrating from one system to another, it’s important to note that the tables in the new application might be structured differently from that in your legacy application, and so these coded joins might not work once the data has been migrated.
Where we typically see these joins break down is when fields from other tables are displayed on the case: user fields, party fields, links to other cases, and workflow statuses. When the join doesn’t work in a migration, what will generally appear is the UUID (universal unique identifier) for the original value, which may look something like this: acde070d-8c4c-4f0d-9d8a-162843c10333. This UUID is stored in the database to represent the value displayed on the front end, which could change: Jane Doe could become Jane Smith over time, but the UUID representing Jane’s record will remain static.
If your data extract for your cases includes the UUID for any field, ensuring that the UUID is also displayed in the extract on the related table will allow us to ensure that this field is migrated properly.
For workflows specifically (your case statuses), it’s likely that we will not be able to recreate the joins, because workflow encoding is specific to the application platform. In these situations we will migrate all your open cases to a default open status (like “In Progress), and all your closed cases to a default closed status.